
Atlan Team
Introduction
In this blog post we are going to be giving a high level overview of a proof of concept tool that we have created using a custom Machine Learning algorithm realised in Python and a C# wrapper to interact with Active Directory.
In Adversary Simulation engagements, or indeed any form of internal penetration test, file shares can be a vast resource of information.
Often developers and system administrators leave passwords unattended and finding these can be a key to the success of the engagement.
As far as the tools we have used, most have been centered around "grepping" lines below and above the word password, looking through files with select file extensions and then relying on the human operator for validation.
We decided to experiement with Machine Learning, in particular Clustering and Classification, to see if we could use these methods to find passwords (and validate them against Active Directory) in accessible file shares.
It is important to note that this tool is a Proof Of Concept (PoC), with the aiming being to encourage the Red Team community to start exploring and experimenting with Machine Learning in their engagements.
While Machine Learning has definitely been a buzz word in our industry, Threat Intelligence does indicate that these sorts of capabilities are being developed and used by Threat Actors.
The sorts of capabilities presented by this tool, can certainly be acheived in other ways, such as using Grepping, Regex queries and similar, however the hope is that the tool is further developed, and it inspires the Red Team community to experiment further - we certainly will be!
The approach is outlined in the sections below.
Data Mining and Sorting
We developed a C# wrapper that interacts with Active Directory and mines information from Active Directory and the network.
It queries Active Directory for all users in the domain and sorts them into a formatted list which is written into the TEMP folder.
It currently supports a single fileshare, that you can specify on the command line, and given appropriate user permissions will search through the file share for files such as BAT, TXT, VBS and SQL files, and other pre-determined file type extensions.
It will then create a combined output of all the files into a single text document, spaced line by line.
A the end of the first step we have compiled a list of Active Directory users, and some raw data to work with.
Piping the Data into the Algorithm
Next the C# wrapper feeds into the Python Machine Learning algorithm and the associated rules that we have developed through training. These are stored as resource files, complied with PyInstaller, and are written to disk, where the model can take input and output.
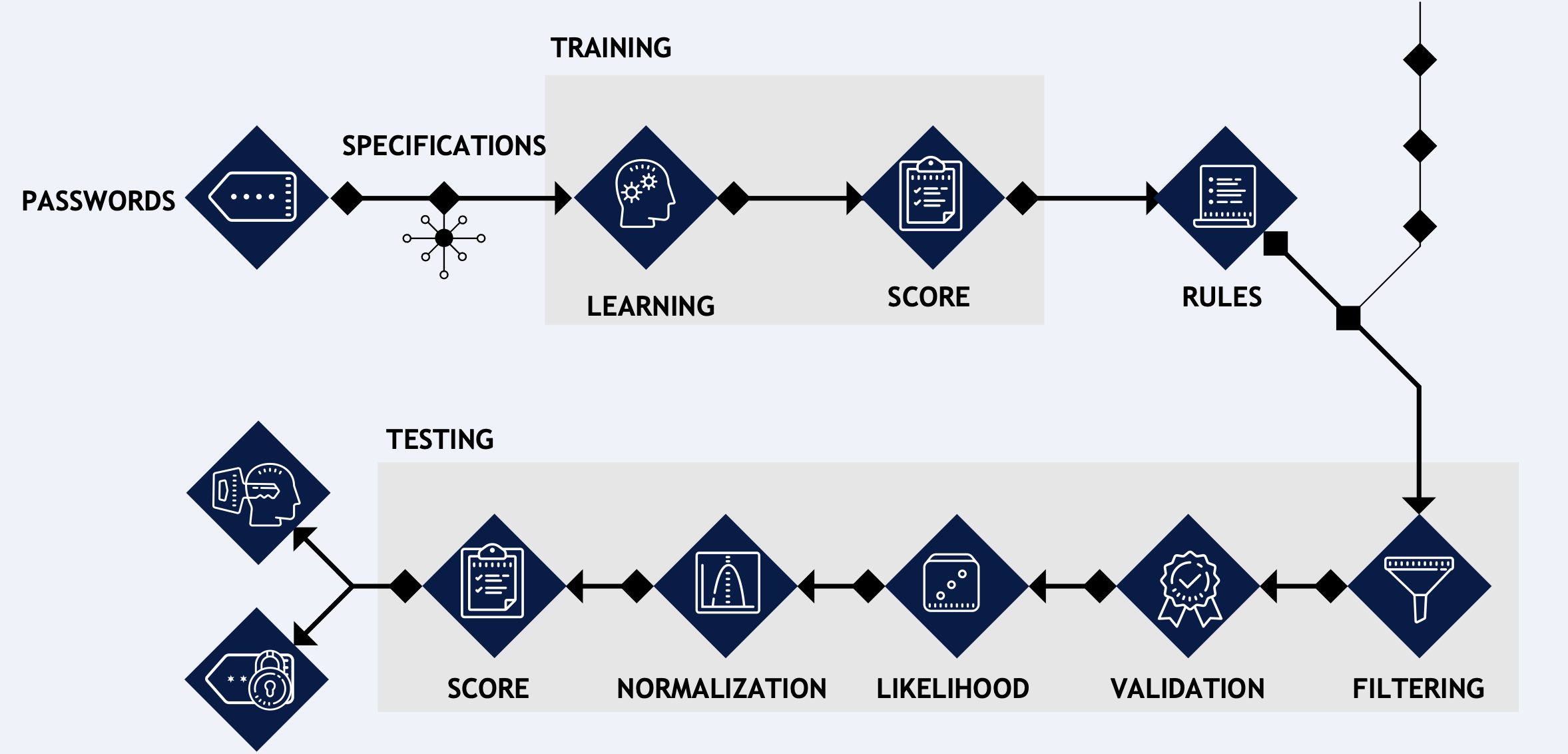
This model’s purpose is to iterate through the raw data compiled by the wrapper trying to calaulate which words may be passwords. This is achieved using an in-house artificial intelligence algorithm based on Machine Learning, whose logic is summarized below.
Training
In order to recognize what is a password and what it is not, the algorithm was trained on randomly generated passwords using a well known open source tool. The training step is one critical step of the Machine Learning process because it will teach the machine how to identify a password.
For this reason, It is essential to provide a good training set which depends on the purpose of the study: do we want to find general passwords or really secure and complex passwords? Trying to get both answers at the same time may result in output that is not useful. The reasons being is that a password might be any sequence of characters, thus it is necessary to identify common rules and patterns that lead to the most probable way to define a password.
Basing on some KPI (i.e. use of characters, special symbols, numbers, uppercases, punctuation…), the algorithm gives a weight to each symbol using the words from the training document, and creates a set of rules.
Filtering
Some words have to be excluded because they might be held to have a good score, but they are not what we are looking for. Examples might be web addresses, bank accounts or credit card numbers.
Also other filters are set, which penalize or exclude special sequences of characters or numbers.
Normalization
How is it possible to define when the score is high? This might be subjective. For this reason, the score is normalized, and then the so called ‘outliers’ are detected based on literature score. The process of normalization transforms the raw score into a new weighted score where it is possible to understand with far less subjectivity how the data is distributed. There are different ways to normalize, and it is necessary to pay attention, because a wrong normalization may lead to different results.
The process of normalization is a wide, complex and important topic. Be sure to follow our next blog posts for more detailed information.
Validation
Words that survive the filtering process are analyzed based on the rules defined during the training session, and a score will be assigned.
When analyzing a word, if a list of common passwords is provided, the algorithm will check if the word matches with one of the common passwords. If not, the machine will apply the learned rules and assign a score (likelihood) to the word.
In other words, the model actually works by assigning a number to each word based on a classification system. This system takes the length of the word, use of characters, symbols and numbers (provided by the training session) and ranks each word giving a final score.
If a word may be a password candidate, a high score of likelihood will be associated, otherwise it will have a low one. Words with a high score are the ones we are interested in.
The logic described above is applied to the document in two ways:
- Pairs user-password: The algorithm analyses only the lines where the username is present, trying to find the associated password (from the username until the end of the line). The list of usernames is provided by the C# wrapper described before in this article.
- Isolated passwords: The algorithm will try to extract isolated passwords analyzing the entire document.
Steps of the algorithm
In learning step the algorithm is fed with a set of known passwords and optional specifications (i.e. symbols to consider as important for defining a password in a specific context). The algorithm will then begin the learning process by calculating symbol occurrences.
The result of the process is a set of rules. If the training is well done, there is no need to repeat the process anymore. With the set of rules, the data to analyze and some other optional input, the algorithm will begin the testing process. Data is filtered (i.e. removing words outside a certain length range, removing e-mails, bank accounts numbers, credit card numbers…) and the filtered set is validated. Note that, before the beginning of the validation, in classic Machine Learning it is necessary to normalize data. In this case, data is described through a single feature (essentially, a number) that wouldn’t give any additional information after a transformation, and therefore this step can be avoided here.
The data is then analyzed based on the rules from the training session, with the goal to find pairs user-password and isolated passwords. The output of this process is a score for each word, that has to be normalized in order to figure out which words are outliers (passwords). A final score is then assigned based on a literature threshold, and the words with score above a certain range will be returned as output.
Output and Verification
The model will perform its assessment of the raw data, and hand over back to the C# wrapper any potential user:password pair combinations that it finds.
The wrapper, having taken over, will perform an authentication check against Active Directory using LDAP a single time for each combination.
At the end of the process, if any passwords have been found, and validated against a Domain Controller, they will echoed into the terminal as valid Active Directory passwords.
Owing to it being developed in C#, the tool can aslo be load into memory as an Assembly using Cobalt Strike, and while not a huge amount of consideration has been paid to Anti Virus & EDR evasion, an up-to-date Windows Defender did not flag any activities as malicious.
Limitations
When we were developing this tool, we did not have access to a large corporate data network. This means that the tools has only been tested in small Active Directory lab environments, and therefore performance issues may arise when large file shares are assessed and therefore the increase in network traffic.
Alongside this, the tool is a work in progress and therefore going forward both the wrapper elements and also the Machine Learning algorithm will be improved upon.
We encourage the community to help us further develop both the wrapper and the Machine Learning model & rules.
TO DO:
- When SharpML is run it will attempt to verify all users that it finds. If a restrictive domain lockout policy exits, it may attempt to verify users multiple times and lock the account out in event of multiple failed authentications
- Some file size limitations need to be implemented in order for larger text based files not to cause a bottle neck when copying the raw data
- Select the option of running multiple file shares simultaneously. By implementing an automatic share finder, allow SharpML to be completely autonomous and scour the whole network
- Improve some program logic, including further options such as the choice of cehcking against 10,000 most common passwords or not
The Tool
This tool was released some years ago, however soon some new tools will be released around the intersection of malware, GAN's, ML, appsec and more so keep any eye out!
Open-source tool
SharpML Codebase
Browse the repository tree and preview files without leaving the page. View the full training.
Training
Machine Learning for Red Teams
Hands-on training on ML foundations, clustering, classification, and model abuse for operators.